 2
2
/ Wt
for t = 1, ..., N
Weighted least squares (WLS) is implemented in SHAZAM by specifying
the name of an appropriate weight variable with the
WEIGHT= option on the OLS command.
The general command format is:
OLS depvar indeps / WEIGHT=weight options
|
where depvar is the dependent variable, indeps
is a list of the explanatory variables, weight is the name of
the weight variable and options is a list of desired options.
Suppose the name of the weight variable is W. SHAZAM makes the following assumption about the form of the error variance:
var(et) =
2
/ Wt
for t = 1, ..., N
where N is the sample size and
2
is an unknown scalar. Note that this assumes that the error
variance is inversely proportional to the weight
variable W. Many textbooks use an error variance
assumption that is proportional to an explanatory variable in the
regression equation. To accomplish this, the inverse of the variable must
be generated and specified as the weight variable on the
WEIGHT= option.
The purpose of weighted least squares estimation is to get more efficient parameter estimates. After model estimation some thought must be given to the computation of an R-square measure, residuals, predicted values, elasticities at the mean etc. The computations used by SHAZAM can be studied.
This example of weighted least squares uses a data set from Greene on state expenditure on public schools. First consider the equation specification. Greene [1993, p.385] recommends using the square of the per capita income variable as an explanatory variable in the regression. The regression specification is:
EXPt =
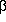 0 +
1
INCOMEt +
2
INCOMEt2 + et
0 +
1
INCOMEt +
2
INCOMEt2 + et
This is an example of a polynomial regression model. Applications of the polynomial regression model are discussed in Griffiths, Hill and Judge [1993, p.337], Gujarati [1995, p.217] and Ramanathan [1995, p.260].
The SHAZAM command file (filename:
WLS.SHA)
that follows constructs the data and runs the model
estimation. Tests for heteroskedasticity are obtained after OLS estimation.
Two alternative assumptions are then made about
the weight variable to use in the weighted least squares estimation.
The first assumption is that the variance is proportional to
income and the second assumption is that the variance
is proportional to the square of income.
SAMPLE 1 51
FORMAT (A8,F6.0,1X,F6.0)
READ (GREENE.txt) STATE EXP INCOME / SKIPLINES=1 FORMAT
* First scale the INCOME data
GENR INCOME=INCOME/1000
* Generate the square of income
GENR INC2=INCOME**2
* Exclude missing values from the analysis
SET MISSVALU=-99
SET SKIPMISS
* Model estimation as reported in Table 14.2 of Greene (1993)
OLS EXP INCOME INC2
* Tests for heteroskedasticity
DIAGNOS / HET
* Get heteroskedasticity-consistent standard errors (Greene, Table 14.3)
OLS EXP INCOME INC2 / HETCOV
*
* Weighted least squares estimation (Greene, Table 14.4, p.398)
* Assumption A : Variance is proportional to INCOME
GENR WT=1/INCOME
OLS EXP INCOME INC2 / WEIGHT=WT PREDICT=YHAT RESID=E
* Test for heteroskedasticity (approx. 1% critical value = 6.64)
GENR E2=E*E
?OLS E2 YHAT
GEN1 LM=$N*$R2
PRINT LM
* Assumption B : Variance is proportional to INCOME**2
GENR WT=1/(INCOME**2)
OLS EXP INCOME INC2 / WEIGHT=WT PREDICT=YHAT RESID=E
GENR E2=E*E
?OLS E2 YHAT
GEN1 LM=$N*$R2
PRINT LM
STOP
|
A note on reading the data : The first column of the
GREENE.txt
data file contains character data. Therefore
a FORMAT command must be used to load the data set into
SHAZAM. The FORMAT option on the READ
command instructs SHAZAM to use the FORMAT command
when reading the data.
Another feature of the data set is that expenditure data is missing for
Wisconsin and has been assigned the code -99SET MISSVALU=-99SET SKIPMISS
Note that the ? prefix to a command instructs SHAZAM to suppress output from the command.
After the WLS estimation if may be sensible to check if there is
still evidence for heteroskedasticity in the errors. The user is
cautioned that the DIAGNOS / HETRESID=
option on the OLS / WEIGHT=
The SHAZAM commands above propose a test
statistic for testing for heteroskedasticity after WLS estimation.
This test corresponds to the first statistic reported on the output
from the DIAGNOS / HET
The test statistic from the first model estimation is reported as:
LM
9.088942
The test statistic from the second model estimation is reported as:
LM
5.068986
These results suggest that the second assumption (variance is proportional to the square of income) is more successful in correcting the observed heteroskedasticity in the equation residuals.
The SHAZAM output can be viewed.
 [SHAZAM Guide home]
[SHAZAM Guide home]
|_SAMPLE 1 51
|_FORMAT (A8,F6.0,1X,F6.0)
|_READ (GREENE.txt) STATE EXP INCOME / SKIPLINES=1 FORMAT
UNIT 88 IS NOW ASSIGNED TO: GREENE.txt
READ USES FORMAT: (A8,F6.0,1X,F6.0)
|_* First scale the INCOME data
|_GENR INCOME=INCOME/1000
|_* Generate the square of income
|_GENR INC2=INCOME**2
|_* Exclude missing values from the analysis
|_SET MISSVALU=-99
|_SET SKIPMISS
|_* Model estimation as reported in Table 14.2 of Greene (1993)
|_OLS EXP INCOME INC2
OBSERVATION 34 IS SKIPPED BECAUSE EXP MISSING
OLS ESTIMATION
50 OBSERVATIONS DEPENDENT VARIABLE= EXP
...NOTE..SAMPLE RANGE SET TO: 1, 51
R-SQUARE = 0.6553 R-SQUARE ADJUSTED = 0.6407
VARIANCE OF THE ESTIMATE-SIGMA**2 = 3212.5
STANDARD ERROR OF THE ESTIMATE-SIGMA = 56.679
SUM OF SQUARED ERRORS-SSE= 0.15099E+06
MEAN OF DEPENDENT VARIABLE = 373.26
LOG OF THE LIKELIHOOD FUNCTION = -271.270
VARIABLE ESTIMATED STANDARD T-RATIO PARTIAL STANDARDIZED ELASTICITY
NAME COEFFICIENT ERROR 47 DF P-VALUE CORR. COEFFICIENT AT MEANS
INCOME -183.42 82.90 -2.213 0.032-0.307 -2.0381 -3.7389
INC2 15.870 5.191 3.057 0.004 0.407 2.8163 2.5074
CONSTANT 832.91 327.3 2.545 0.014 0.348 0.0000 2.2315
|_* Tests for heteroskedasticity
|_DIAGNOS / HET
OBSERVATION 34 IS SKIPPED BECAUSE EXP MISSING
DEPENDENT VARIABLE = EXP 50 OBSERVATIONS
REGRESSION COEFFICIENTS
-183.420294634 15.8704226661 832.914356455
HETEROSKEDASTICITY TESTS
CHI-SQUARE D.F. P-VALUE
TEST STATISTIC
E**2 ON YHAT: 13.401 1 0.00025
E**2 ON YHAT**2: 14.692 1 0.00013
E**2 ON LOG(YHAT**2): 11.408 1 0.00073
E**2 ON LAG(E**2) ARCH TEST: 0.339 1 0.56048
LOG(E**2) ON X (HARVEY) TEST: 4.825 2 0.08958
ABS(E) ON X (GLEJSER) TEST: 11.952 2 0.00254
E**2 ON X TEST:
KOENKER(R2): 15.834 2 0.00036
B-P-G (SSR) : 18.903 2 0.00008
...MATRIX IS NOT POSITIVE DEFINITE..FAILED IN ROW 4
E**2 ON X X**2 (WHITE) TEST:
KOENKER(R2): ********** 4 *********
B-P-G (SSR) : ********** 4 *********
...MATRIX IS NOT POSITIVE DEFINITE..FAILED IN ROW 4
E**2 ON X X**2 XX (WHITE) TEST:
KOENKER(R2): ********** 5 *********
B-P-G (SSR) : ********** 5 *********
|_* Get heteroskedasticity-consistent standard errors (Greene, Table 14.3)
|_OLS EXP INCOME INC2 / HETCOV
OBSERVATION 34 IS SKIPPED BECAUSE EXP MISSING
OLS ESTIMATION
50 OBSERVATIONS DEPENDENT VARIABLE= EXP
...NOTE..SAMPLE RANGE SET TO: 1, 51
USING HETEROSKEDASTICITY-CONSISTENT COVARIANCE MATRIX
R-SQUARE = 0.6553 R-SQUARE ADJUSTED = 0.6407
VARIANCE OF THE ESTIMATE-SIGMA**2 = 3212.5
STANDARD ERROR OF THE ESTIMATE-SIGMA = 56.679
SUM OF SQUARED ERRORS-SSE= 0.15099E+06
MEAN OF DEPENDENT VARIABLE = 373.26
LOG OF THE LIKELIHOOD FUNCTION = -271.270
VARIABLE ESTIMATED STANDARD T-RATIO PARTIAL STANDARDIZED ELASTICITY
NAME COEFFICIENT ERROR 47 DF P-VALUE CORR. COEFFICIENT AT MEANS
INCOME -183.42 124.3 -1.476 0.147-0.210 -2.0381 -3.7389
INC2 15.870 8.300 1.912 0.062 0.269 2.8163 2.5074
CONSTANT 832.91 460.9 1.807 0.077 0.255 0.0000 2.2315
|_*
|_* Weighted least squares estimation (Greene, Table 14.4, p.398)
|_* Assumption A : Variance is proportional to INCOME
|_GENR WT=1/INCOME
|_OLS EXP INCOME INC2 / WEIGHT=WT PREDICT=YHAT RESID=E
OBSERVATION 34 IS SKIPPED BECAUSE EXP MISSING
OLS ESTIMATION
50 OBSERVATIONS DEPENDENT VARIABLE= EXP
...NOTE..SAMPLE RANGE SET TO: 1, 51
SUM OF LOG(SQRT(ABS(WEIGHT))) = -0.22015
R-SQUARE = 0.6274 R-SQUARE ADJUSTED = 0.6115
VARIANCE OF THE ESTIMATE-SIGMA**2 = 2978.8
STANDARD ERROR OF THE ESTIMATE-SIGMA = 54.578
SUM OF SQUARED ERRORS-SSE= 0.14000E+06
MEAN OF DEPENDENT VARIABLE = 364.48
LOG OF THE LIKELIHOOD FUNCTION = -269.602
VARIABLE ESTIMATED STANDARD T-RATIO PARTIAL STANDARDIZED ELASTICITY
NAME COEFFICIENT ERROR 47 DF P-VALUE CORR. COEFFICIENT AT MEANS
INCOME -161.23 84.48 -1.908 0.062-0.268 -1.8654 -3.3061
INC2 14.475 5.377 2.692 0.010 0.365 2.6312 2.2583
CONSTANT 746.36 328.2 2.274 0.028 0.315 0.0000 2.0477
|_* Test for heteroskedasticity (approx. 1% critical value = 6.64)
|_ GENR E2=E*E
..OBSERVATION 34 IS ASSIGNED MISSING CODE= -99.
|_ ?OLS E2 YHAT
OBSERVATION 34 IS SKIPPED BECAUSE YHAT MISSING
OBSERVATION 34 IS SKIPPED BECAUSE E2 MISSING
|_ GEN1 LM=$N*$R2
..NOTE..CURRENT VALUE OF $N = 50.000
..NOTE..CURRENT VALUE OF $R2 = 0.18178
|_ PRINT LM
LM
9.088942
|_* Assumption B : Variance is proportional to INCOME**2
|_GENR WT=1/(INCOME**2)
|_OLS EXP INCOME INC2 / WEIGHT=WT PREDICT=YHAT RESID=E
OBSERVATION 34 IS SKIPPED BECAUSE EXP MISSING
OLS ESTIMATION
50 OBSERVATIONS DEPENDENT VARIABLE= EXP
...NOTE..SAMPLE RANGE SET TO: 1, 51
SUM OF LOG(SQRT(ABS(WEIGHT))) = -0.86795
R-SQUARE = 0.5983 R-SQUARE ADJUSTED = 0.5812
VARIANCE OF THE ESTIMATE-SIGMA**2 = 2784.3
STANDARD ERROR OF THE ESTIMATE-SIGMA = 52.766
SUM OF SQUARED ERRORS-SSE= 0.13086E+06
MEAN OF DEPENDENT VARIABLE = 356.60
LOG OF THE LIKELIHOOD FUNCTION = -268.562
VARIABLE ESTIMATED STANDARD T-RATIO PARTIAL STANDARDIZED ELASTICITY
NAME COEFFICIENT ERROR 47 DF P-VALUE CORR. COEFFICIENT AT MEANS
INCOME -139.93 87.21 -1.605 0.115-0.228 -1.6730 -2.8830
INC2 13.113 5.637 2.326 0.024 0.321 2.4256 2.0193
CONSTANT 664.58 333.6 1.992 0.052 0.279 0.0000 1.8637
|_ GENR E2=E*E
..OBSERVATION 34 IS ASSIGNED MISSING CODE= -99.
|_ ?OLS E2 YHAT
OBSERVATION 34 IS SKIPPED BECAUSE YHAT MISSING
OBSERVATION 34 IS SKIPPED BECAUSE E2 MISSING
|_ GEN1 LM=$N*$R2
..NOTE..CURRENT VALUE OF $N = 50.000
..NOTE..CURRENT VALUE OF $R2 = 0.10138
|_ PRINT LM
LM
5.068986
|_STOP
[SHAZAM Guide home]